1. 子查询(Subqueries): 子查询是在另一个查询内部嵌套的查询。它们能够用于核算值、挑选行或生成数据集。子查询能够出现在 SELECT、WHERE、HAVING 和 FROM 子句中。
```sql SELECT FROM orders WHERE order_id IN ; ```
2. 联合查询(Union Queries): 联合查询答应你将多个 SELECT 句子的成果合并到一个成果会集。UNION ALL 会包含一切成果,包含重复的行,而 UNION 会主动去除重复的行。
```sql SELECT name FROM customers UNION SELECT name FROM suppliers; ```
3. 聚合函数(Aggregate Functions): 聚合函数对一组值履行核算并回来单个值。常见的聚合函数包含 COUNT、SUM、AVG、MAX 和 MIN。
```sql SELECT COUNT FROM products; ```
4. 分组(Grouping): GROUP BY 子句用于将成果集按一个或多个列进行分组,以便对每个组履行聚合函数。
```sql SELECT category, AVG AS average_price FROM products GROUP BY category; ```
5. HAVING 子句: HAVING 子句用于对分组后的成果进行挑选。它一般与 GROUP BY 子句一同运用。
```sql SELECT category, AVG AS average_price FROM products GROUP BY category HAVING average_price > 100; ```
6. 衔接(Joins): 衔接答应你依据两个或多个表中的列之间的联系来检索数据。常见的衔接类型包含内衔接(INNER JOIN)、左衔接(LEFT JOIN)、右衔接(RIGHT JOIN)和全衔接(FULL JOIN)。
```sql SELECT customers.name, orders.order_id FROM customers INNER JOIN orders ON customers.customer_id = orders.customer_id; ```
7. 索引(Indexes): 索引是数据库表中的一个特别的数据结构,它能够协助进步查询速度。在常常用于查找、排序或分组的列上创立索引能够明显进步查询功用。
```sql CREATE INDEX idx_customer_id ON customers; ```
8. 存储进程(Stored Procedures): 存储进程是一组为了完结特定功用的 SQL 句子调集,它们被存储在数据库中并能够被屡次调用。存储进程能够承受参数、回来成果集以及履行事务。
```sql DELIMITER // CREATE PROCEDURE GetOrdersByCustomer BEGIN SELECT FROM orders WHERE customer_id = cust_id; END // DELIMITER ; ```
9. 触发器(Triggers): 触发器是当特定事情(如 INSERT、UPDATE 或 DELETE)产生时主动履行的数据库操作。它们能够用于审计、数据完整性查看或其他主动化使命。
```sql CREATE TRIGGER after_order_insert AFTER INSERT ON orders FOR EACH ROW BEGIN INSERT INTO order_log VALUES qwe2; END; ```
10. 事务(Transactions): 事务是一系列操作,它们要么悉数成功,要么悉数失利。事务能够保证数据的一致性和完整性。
```sql START TRANSACTION; INSERT INTO orders VALUES qwe2; INSERT INTO order_details VALUES ; COMMIT; ```
11. 视图(Views): 视图是一个虚拟表,其内容由查询界说。视图能够简化杂乱的查询,并答应用户拜访特定的数据子集。
```sql CREATE VIEW customer_orders AS SELECT customers.name, orders.order_id, orders.order_date FROM customers JOIN orders ON customers.customer_id = orders.customer_id; ```
12. 窗口函数(Window Functions): 窗口函数答应你在每个分组内部进行核算,而不需要运用 GROUP BY 子句。它们能够用于核算排名、累计总和等。
```sql SELECT product_name, price, RANK OVER AS price_rank FROM products; ```
13. 正则表达式(Regular Expressions): MySQL 支撑运用正则表达式进行字符串查找和替换。这能够用于杂乱的字符串操作,如查找形式、替换文本等。
```sql SELECT FROM products WHERE product_name REGEXP '^'; ```
14. JSON 数据类型: MySQL 5.7 及以上版别支撑 JSON 数据类型,能够存储 JSON 文档。能够运用 JSON 函数来查询和修正 JSON 数据。
```sql SELECT product_name, JSON_EXTRACT FROM products; ```
15. 暂时表(Temporary Tables): 暂时表是在当时会话中创立的表,它们在会话结束时主动毁掉。暂时表能够用于存储中心成果或进行杂乱的核算。
```sql CREATE TEMPORARY TABLE temp_table AS SELECT FROM products WHERE price > 100; ```
16. 安全性和权限办理: MySQL 供给了强壮的安全性和权限办理功用,能够操控用户对数据库的拜访。能够运用 GRANT 和 REVOKE 句子来分配和吊销权限。
```sql GRANT SELECT ON database_name. TO 'user'@'host'; REVOKE SELECT ON database_name. FROM 'user'@'host'; ```
17. 备份和康复: 定时备份数据库是保证数据安全的重要措施。MySQL 供给了多种备份和康复办法,包含物理备份、逻辑备份和二进制日志。
```bash mysqldump u username p database_name > backup.sql ```
18. 功用优化: 功用优化是保证数据库高效运转的要害。这包含索引优化、查询优化、服务器装备调整等。
```sql EXPLAIN SELECT FROM products WHERE price > 100; ```
19. 事情调度器(Event Scheduler): 事情调度器答应你计划在特定时刻履行数据库操作,如定时备份、数据整理等。
```sql CREATE EVENT daily_backup ON SCHEDULE EVERY 1 DAY DO BEGIN CALL backup_database; END; ```
20. 全文查找(FullText Search): MySQL 支撑全文查找,能够用于在文本列中查找要害字或短语。
```sql SELECT FROM articles WHERE MATCH AGAINST; ```
这些高档查询技巧能够协助你更有效地运用 MySQL,进步查询功用,并完结更杂乱的数据操作。记住,依据你的详细需求和数据库结构,挑选适宜的查询办法和优化战略。
MySQL 高档查询技巧与实战解析
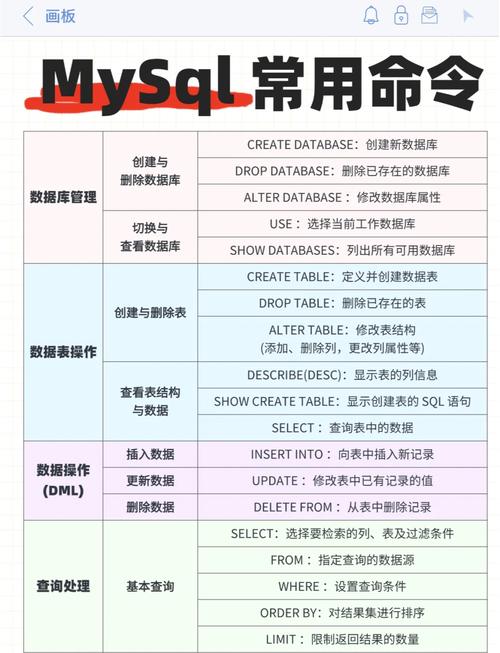
跟着数据量的不断增加和事务需求的日益杂乱,MySQL数据库的高档查询技巧变得尤为重要。本文将深入探讨MySQL高档查询的相关常识,包含衔接查询、子查询、聚合函数、存储进程等,并结合实际事例进行解析,协助您提高数据库查询功率。
一、衔接查询

衔接查询是MySQL中一种强壮的数据检索方法,它答应用户从两个或多个表中依据相关列之间的联系提取数据。以下是几种常见的衔接查询类型:
1. 内衔接(INNER JOIN)
内衔接只回来两个表中匹配的行。以下是一个示例,假定咱们有两个表:`employees`(职工表)和`departments`(部分表),咱们想要查询每个部分及其对应的职工信息。
SELECT employees.name, departments.department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.id;
2. 左衔接(LEFT JOIN)
左衔接回来左表(`employees`)的一切行,即便右表(`departments`)中没有匹配的行。假如右表中没有匹配的行,则成果会集右表的相关列将显现为NULL。
SELECT employees.name, departments.department_name
FROM employees
LEFT JOIN departments ON employees.department_id = departments.id;
3. 右衔接(RIGHT JOIN)
右衔接与左衔接相反,回来右表(`departments`)的一切行,即便左表(`employees`)中没有匹配的行。
SELECT employees.name, departments.department_name
FROM employees
RIGHT JOIN departments ON employees.department_id = departments.id;
4. 全衔接(FULL JOIN)
全衔接回来两个表中一切匹配的行,假如左表或右表中没有匹配的行,则成果会集相应的列将显现为NULL。
SELECT employees.name, departments.department_name
FROM employees
FULL JOIN departments ON employees.department_id = departments.id;
二、子查询
子查询是一种在查询中嵌套另一个查询的方法,它能够出现在SELECT、FROM或WHERE子句中。以下是几种常见的子查询类型:
1. 挑选子查询
挑选子查询用于从子查询中获取数据,并将其作为外层查询的条件。
SELECT name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
2. 行子查询
行子查询用于比较两个表中的行,并回来匹配的行。
SELECT a.name, b.department_name
FROM employees a
JOIN departments b ON a.department_id = b.id
WHERE a.department_id IN (SELECT department_id FROM employees WHERE name = '张三');
三、聚合函数
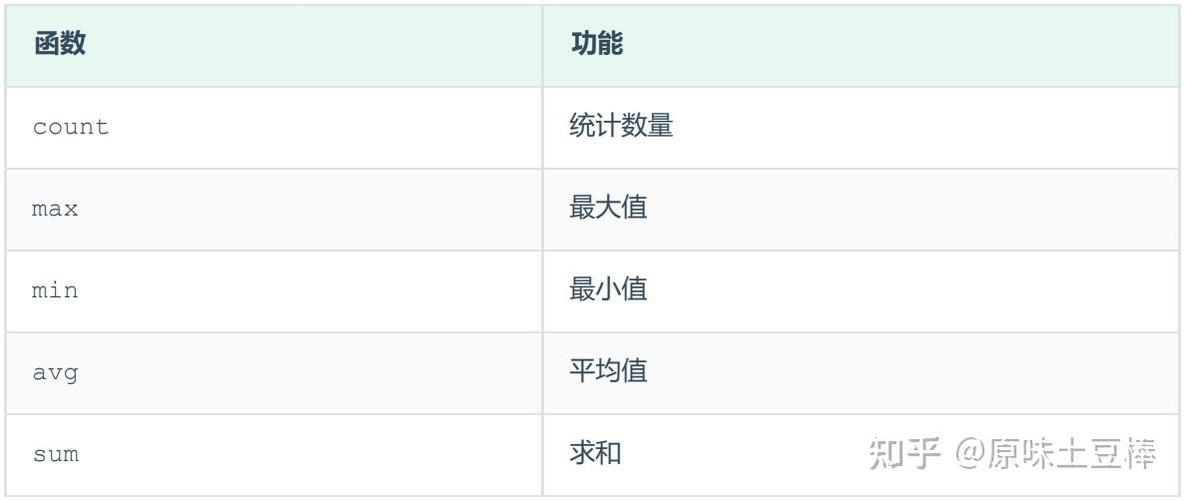
聚合函数用于对多行数据履行核算并回来单个值。以下是几种常见的聚合函数:
1. SUM
核算指定列的总和。
SELECT SUM(salary) AS total_salary
FROM employees;
2. COUNT
核算指定列的行数。
SELECT COUNT() AS total_employees
FROM employees;
3. AVG
核算指定列的平均值。
SELECT AVG(salary) AS average_salary
FROM employees;
4. MAX
回来指定列的最大值。
SELECT MAX(salary) AS max_salary
FROM employees;
5. MIN
回来指定列的最小值。
SELECT MIN(salary) AS min_salary
FROM employees;
四、存储进程

存储进程是一组为了完结特定功用的SQL句子调集,它能够在数据库中存储并重复运用。以下是创立一个简略存储进程的示例:
DELIMITER //
CREATE PROCEDURE GetEmployeeDetails(IN emp_id INT)
BEGIN
SELECT FROM employees WHERE id = emp_id;
END //
DELIMITER ;
经过以上示例,咱们能够看到MySQL高档查询在处理杂乱事务需求时的强壮功用。把握这些技巧,将有助于您在