1. LIKE 操作符: `LIKE` 操作符用于在 `WHERE` 子句中查找列中的特定形式。其根本语法如下: ```sql SELECT column1, column2, ... FROM table_name WHERE column1 LIKE pattern; ``` 其间 `pattern` 是要查找的形式。
2. 通配符: `%`:代表恣意数量的字符(包括零个字符)。 `_`:代表一个字符。
4. 留意事项: 运用 `LIKE` 操作符时,形式匹配不区别大小写。 假如形式中有特别字符(如 `%` 或 `_`),需求运用转义字符(默以为反斜杠 ``)来表明它们。例如,查找包括 `%` 的记载:`WHERE column LIKE '%%%' ESCAPE ''`。
5. 功能: 运用 `LIKE` 操作符进行含糊查找时,功能可能会受到影响,尤其是当形式以通配符开始时(如 `'�c'`)。这是由于数据库需求扫描整个表来查找匹配的记载。
6. 优化: 假如常常需求进行含糊查找,能够考虑运用全文索引(FullText Index)来进步功能。 另一种办法是运用其他查找技能,如 Elasticsearch,它们专门为查找和索引很多文本数据而规划。
MySQL含糊查找优化攻略
在数据库办理中,含糊查找是一种常见的查询办法,它答运用户依据部分信息来查找数据。MySQL作为一款广泛运用的数据库办理体系,供给了多种含糊查找的办法。当数据量增大时,含糊查找可能会变得功率低下,影响用户体会。本文将具体介绍MySQL含糊查找的优化办法,协助您进步查找功能。
运用索引

索引的重要性
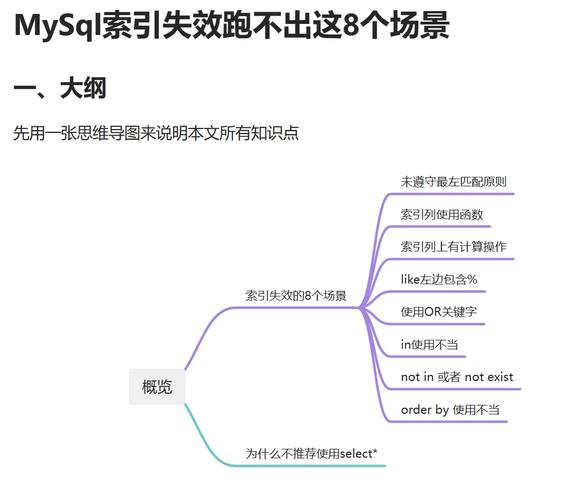
运用索引是优化MySQL含糊查找的最根本办法。在查找的字段上增加索引,能够大大进步查找速度。
在MySQL中,能够运用`CREATE INDEX`句子创立索引。例如,假如您常常依据用户名进行含糊查找,能够在用户名字段上创立索引:
```sql
CREATE INDEX idx_username ON users(username);
需求留意的是,索引并非全能。过多的索引会增加数据库的保护本钱,并可能下降刺进和更新操作的功能。因而,在增加索引之前,应细心考虑索引的必要性。
运用全文索引
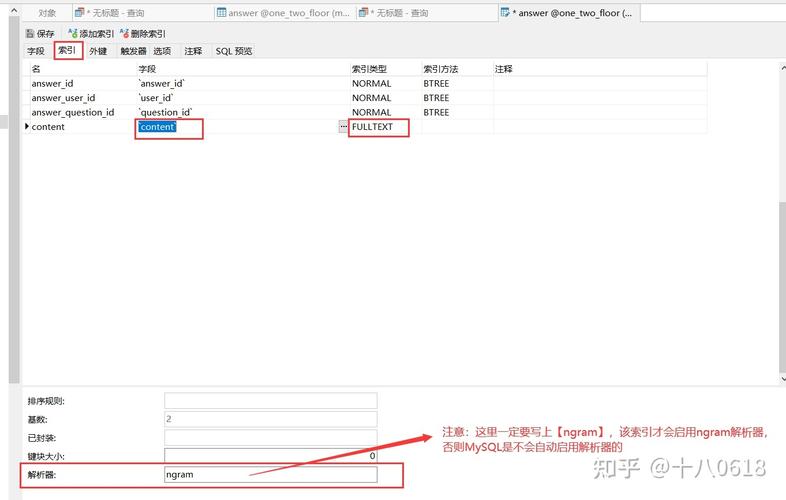
全文索引的优势
全文索引是MySQL供给的一种高档索引类型,能够快速地查找文本数据。与一般索引不同的是,全文索引能够查找文本中的恣意一段内容,而不是只能查找整个单词。
全文索引适用于文本字段,如文章、博客帖子等。在创立全文索引时,能够运用`FULLTEXT`关键字:
```sql
ALTER TABLE articles ADD FULLTEXT(content);
全文索引在InnoDB和MyISAM表上均可运用。在InnoDB表中,全文索引默许是可更新的,而在MyISAM表中,全文索引是不行更新的。
运用缓存

缓存的效果
关于常常被查找的数据,能够将其缓存在内存中,这样能够削减对数据库的拜访次数,进步查找速度。
能够运用Redis等缓存东西来完成缓存。以下是一个简略的示例,运用Redis缓存用户信息:
```python
import redis
连接到Redis服务器
cache = redis.Redis(host='localhost', port=6379, db=0)
查找用户信息
def search_user(username):
查看缓存中是否有用户信息
if cache.exists(username):
return cache.get(username).decode()
else:
从数据库中获取用户信息
user_info = get_user_info_from_db(username)
将用户信息存入缓存
cache.setex(username, 3600, user_info)
return user_info
获取用户信息
def get_user_info_from_db(username):
从数据库中获取用户信息
...
return user_info
运用分词技能
分词技能的运用
分词技能能够将文本数据分解成更小的单元,如单词或短语,然后进步查找功率。
在MySQL中,能够运用第三方分词库,如jieba或SnowNLP等。以下是一个运用jieba进行分词的示例:
```python
import jieba
分词
def segment_text(text):
return list(jieba.cut(text))
示例
text = \