1. Faiss:由Facebook AI Research开发,是一个用于高效类似性查找和密布向量聚类的库。它支撑多种间隔衡量,如欧几里得间隔、余弦类似度等,而且能够在CPU和GPU上运转。
2. Annoy(Approximate Nearest Neighbors Oh Yeah):由 Spotify 开发,是一个用于高效近似最近邻查找的库。它支撑多种间隔衡量,如欧几里得间隔、曼哈顿间隔等,而且能够在CPU和GPU上运转。
3. Milvus:由Zilliz开发,是一个用于高效类似性查找的向量数据库。它支撑多种间隔衡量,如欧几里得间隔、余弦类似度等,而且能够在CPU和GPU上运转。
4. NMSLIB(NonMetric Space Library):是一个用于非衡量空间查找的库,支撑多种间隔衡量,如欧几里得间隔、余弦类似度等。它能够在CPU和GPU上运转。
5. Pinecone:尽管Pinecone自身是一个商业产品,但它供给了一个开源的客户端库,能够与多种向量数据库后端(如Faiss、Annoy等)一同运用。
6. Weaviate:是一个用于高效类似性查找的向量数据库,支撑多种间隔衡量,如欧几里得间隔、余弦类似度等。它能够在CPU和GPU上运转,而且支撑多种编程言语。
7. Qdrant:是一个高性能、可扩展的向量数据库,支撑多种间隔衡量,如欧几里得间隔、余弦类似度等。它能够在CPU和GPU上运转,而且支撑多种编程言语。
8. Elasticsearch:尽管Elasticsearch主要是一个查找引擎,但它也支撑向量查找,能够经过插件或自定义脚本完成。
9. TimescaleDB:是一个时间序列数据库,但它也支撑向量查找,能够经过插件或自定义脚本完成。
10. ClickHouse:是一个高性能、可扩展的列式数据库,但它也支撑向量查找,能够经过插件或自定义脚本完成。
请注意,这些开源向量数据库各有优缺点,挑选哪个取决于您的详细需求和运用场景。主张您在做出挑选之前,细心研讨每个项目的文档和社区支撑状况。
开源向量数据库:探究高效数据检索的未来
跟着大数据和人工智能技术的飞速发展,向量数据库作为一种新式的数据库办理体系,逐步成为数据存储和检索的重要东西。本文将介绍一些盛行的开源向量数据库,并剖析它们的特色和适用场景。
什么是向量数据库?
向量数据库是一种专门用于存储和检索高维向量数据的数据库。它将数据存储为向量,并使用向量之间的类似性进行查找和检索。这种数据库特别适宜处理图画、音频、文本等非结构化数据。
开源向量数据库的优势

开源向量数据库具有以下优势:
本钱效益:开源软件一般免费,降低了企业的本钱。
灵敏性:用户能够依据自己的需求进行定制和扩展。
社区支撑:开源项目一般具有活泼的社区,能够供给技术支撑和沟通。
盛行的开源向量数据库

Milvus
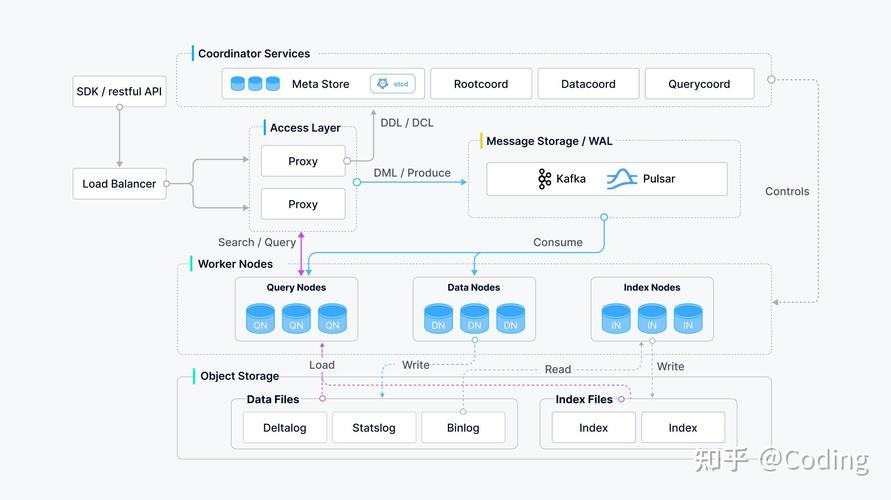
Milvus 是由 Zilliz 开发的一款开源向量数据库,支撑高效的向量存储和类似度查找功用。它具有以下特色:
分布式架构:支撑大规模数据存储和查询。
多种索引算法:支撑多种索引算法,如IVF、HNSW等。
多种编程言语支撑:支撑 C 、Python、Java 等多种编程言语。
FAISS

FAISS 是由 Facebook 的人工智能研讨团队开发的一款高性能向量检索库。它具有以下特色:
高效查找:支撑快速类似性查找和聚类。
GPU 加快:支撑在 GPU 上进行核算,进步查找功率。
多种编程言语支撑:支撑 C 、Python 等多种编程言语。
Qdrant
Qdrant 是一款高可用性、易用性的开源向量数据库。它具有以下特色:
实时更新:支撑实时更新和过滤。
多种索引算法:支撑多种索引算法,如IVF、HNSW等。
RESTful API:供给 RESTful API,便利与其他体系集成。
Weaviate
Weaviate 是一款根据 GraphQL 的开源向量数据库,内置嵌入生成。它具有以下特色:
语义查找:支撑向量检索、分类和语义查找。
多种存储后端:支撑 S3 和内置存储。
多种编程言语支撑:支撑 GraphQL、REST 等多种协议。
Pinecone

Pinecone 是一款彻底保管的向量数据库,易于集成和扩展。它具有以下特色:
实时在线更新:支撑实时在线更新。
多种索引算法:支撑多种索引算法,如IVF、HNSW等。
多种编程言语支撑:支撑 Python、Java 等多种编程言语。
开源向量数据库为数据存储和检索供给了高效、灵敏的解决方案。挑选适宜的向量数据库能够协助企业更好地处理和剖析数据,从而在人工智能和大数据范畴取得成功。

